ЁЁЁЁбыЙуЭјЩЯКЃ5дТ28ШеЯћЯЂЃЈМЧепЬЦЦцдЦЃЉЁАДЬЪЗЁБЕФЁАДЬЁБЃЌбеецЧфЮЊЪВУДаДГЩЁАpЁБЃПНќШеЃЌгаЙиЁАбеецЧфаДДэСЫзжЁБЕФЯћЯЂдкЭјЩЯв§Ц№ШШвщЃЌЛЊЖЋЪІЗЖДѓбЇНЬЪІзЅзЁетИіЦѕЛњЃЌдЫгУИУаЃЭЦГіЕФЁАжЧФмМьЫїжаЙњЮФзжЪ§ОнПтЁБИјЭЌбЇЩЯСЫвЛПЮЃКдРДЃЌЕБЪБЕФЁАДЬЁБДѓИХТЪаДГЩЁАpЁБЃЌЖјетИіЁАpЁБжаЕФЁАМаЁБЃЌОЭЪЧЁАcЁБздЧиККЮФзжвдРДЕФБфаЮЁЃЁАcЁБзжжЎаЮЃЌШЁЯѓгкЁАЪїФОЕФДЬУЂЁБЃЌвВОЭЪЧЯШЧиЪБДњЕФЁАДЬЁБЁЃ
ЁЁЁЁНёЬьЃЈ28ШеЃЉЩЯЮчЃЌЛЊЖЋЪІЗЖДѓбЇжаЙњЮФзжбаОПгыгІгУжааФЃЈЯТГЦЁАЮФзжжааФЁБЃЉОйааЁАРфУХОјбЇЁБзЈвЕЁАаТЮФПЦЁБНЈЩшГЩЙћЗЂВМЛсЁЃдкДЫДЮНЬбЇжаЗЂЛгДѓзїгУЕФЪ§ОнПтЃЌОЭЪЧЮФзжжааФНќШебаЗЂГЩЙІЕФЁАжЧФмаЭжаЙњЮФзжЪ§зжЦНЬЈЁБЪ§ОнПтЯЕСажЎвЛЁЃ
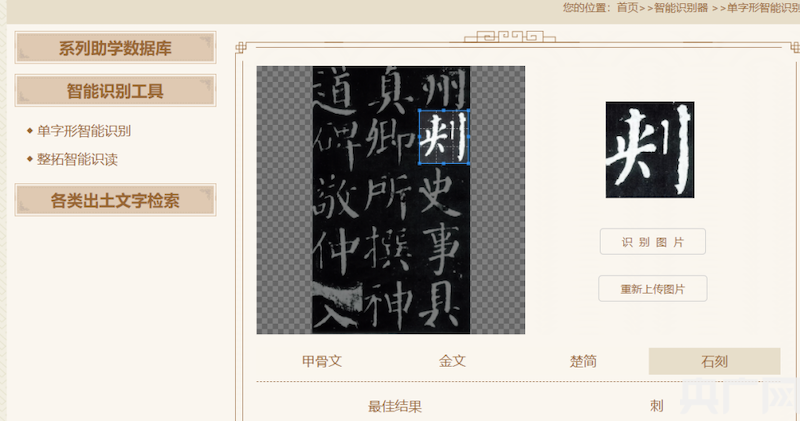
ЁЁЁЁжЧФмЪЖБ№ЁАДЬЁБзжЃЈбыЙуЭјЗЂ ЛЊЖЋЪІЗЖДѓбЇЙЉЭМЃЉ
ЁЁЁЁОнНщЩмЃЌИУЁАжЧФмаЭжаЙњЮФзжЪ§зжЦНЬЈЁБвдЙХЮФзжМАРњДњГіЭСЪЕЮяЮФзжзЪСЯЕФЪ§зжЛЏЮЊФПБъЃЌздЩЯЪРМЭ90ФъДњКѓЦкПЊЪМЦєЖЏЃЌЦфНЈЩшГЩЙћдјЖрДЮЪЕЯжКЃФкЭтЪзДДадЭЛЦЦЃЌШч2003ФъЃЌЭЦГіЪзИіЯШЧиЙХЮФзжЪ§ОнПтЕФе§ЪНГіАцГЩЙћЯЕСаЁЖЩЬжмН№ЮФЪ§зжЛЏДІРэЯЕЭГЁЗКЭЁЖеНЙњГўЮФзжЪ§зжЛЏДІРэЯЕЭГЁЗЃЛ2019Фъе§ЪНЗЂВМЙХЮФзжжЧФмЪЖБ№ЙЄОпЁАЩЬжмН№ЮФжЧФмОЕЁБЁЃдкДЫЛљДЁЩЯЃЌ2020ФъвдРДЃЌЮФзжжааФгжЯрМЬПЊЗЂСЫЖржжГіЭСЮФзжжЧФмЭМЯёЪЖБ№ЯЕЭГЃЌВЂЭъГЩЭМЯёЪЖБ№ЙЄОпгыЪ§ОнПтЕФгааЇНсКЯЃЌДДНЈСЫжЧФмаЭЙХЮФзжЪ§зжЦНЬЈЁЃ
ЁЁЁЁетвЛЭЛЦЦЃЌЖдЙХЮФзжЭМЯёЪЖБ№ЖјбдЃЌгЊдьСЫзюРэЯыЕФЁАбљБОПтЁБЃЌЮЊНјвЛВНбаЗЂКЭММЪѕЭЛЦЦДђдьСЫЗѕЛЏЦНЬЈЁЃЖдГіЭСЙХЮФзжЮФзжЪ§ОнПтЖјбдЃЌЯћГ§СЫСНИіУЄЕуЃКвЛЪЧВЛЪЖжЎзжЪ§ОнПтМьЫїВщбЏУЄЕуЁЃШЅГ§СЫЪ§ОнПтЪЙгУепЕФзЈвЕжЊЪЖУХМїЃЌДѓДѓЬсЩ§СЫЪ§ОнПтЕФЩчЛсЗўЮёЙІФмЃЛЖўЪЧЭМЯёдиЬхВФСЯЕФМЦЫуЛњздЖЏЪЖБ№УЄЕуЁЃГѕВНЪЕЯжЪ§зжЦНЬЈжаЭМЦЌдиЬхВФСЯгызжЗћМЏдиЬхВФСЯЕФздЖЏЪ§зжЙиСЊЃЌНјЖјгЊдьСЫЙХЮФзжзЪСЯДѓЪ§ОнЩњГЩКЭЛњЦїбЇЯАЕФЛЗОГЃЌЮЊИїжжбаОПзЈЬтЕФжЧФмЛЏЪжЖЮНщШыДДдьСЫЬѕМўЁЃ
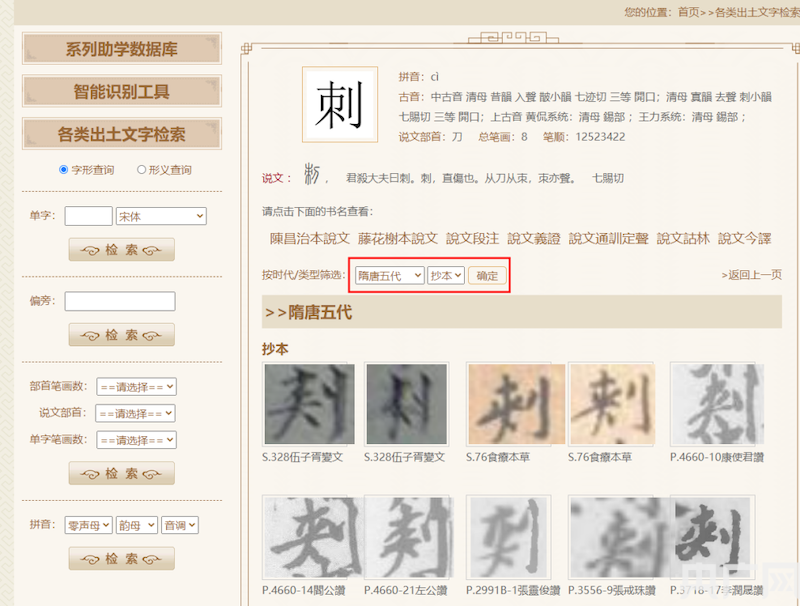
ЁЁЁЁжЧФмЪЖБ№ЁАДЬЁБзжЙиСЊМьЫїЃЈбыЙуЭјЗЂ ЛЊЖЋЪІЗЖДѓбЇЙЉЭМЃЉ
ЁЁЁЁГ§СЫгУЭМЯёЪЖБ№ММЪѕНЋжаЙњЮФзжЪ§зжЦНЬЈЬсЩ§ЕНЁАжЧФмЛЏЁБМЖБ№вдЭтЃЌИУЪ§зжЦНЬЈЛЙОпгаЁАИїЖЯДњИїРраЭГіЭСЪЕЮяЮФзжзЪСЯШЋИВИЧЁБЁАШЋзжЗћМьЫїВщбЏЭЛЦЦЁБЁАЖрВуДЮЩюЖШМгЙЄгызЈЬтадЪ§ОнПтЯЕСааЮГЩЁБЕШДДаТЙІФмЁЃ
ЁЁЁЁОнНщЩмЃЌФПЧАФГаЉКЃФкЭтЯрЙиДѓбЇбаОПЛњЙЙЫфШЛвВгаДЫРрЭјТчЪ§ОнПтЃЌЕЋВФСЯИВИЧЖМжЙгкФГИіБ№ЖЯДњЛђВФСЯРраЭЁЃЁАжЧФмаЭжаЙњЮФзжЪ§зжЦНЬЈЁБЫљАќКЌЕФЮФзжВФСЯИВИЧСЫздвѓЩЬМзЙЧЕНУїЧхЮФзжећИіККзжЗЂеЙЪЗЕФИїжжЪБЖЮЕФИїжжРраЭЃЛЯШЧиВПЗжЃЌЛљБОФвРЈФПЧАвбЙЋВМЕФзЪСЯЃЛЯШЧивдКѓЛуМЏСЫИїЪБЖЮжївЊДњБэадВФСЯЁЃвђДЫЪ§зжЦНЬЈПАГЦЕчзгАцЁАзжКЃЁБЃЌПЩвдЬсЙЉИВИЧећИіККзжЗЂеЙЪЗЕФЯрЙиЮФзжаХЯЂЕФЖЈСПадМьЫїВщбЏЁЃ
ЁЁЁЁСэвЛЗНУцЃЌГіЭСЮФзжЪ§ОнПтНЈЩшУцСйзжЗћМЏжЇГжЕФРЇФбЃКвЛЪЧШБзжЃЌМДДцдкДѓСПМЏЭтзжЃЛЖўЪЧгазжВЛФмгУЃЌ9ЭђЖрвбБрТыККзжжЛгаGBKЕФ20902ИіПЩвдгУгкЪ§ОнПтКЭЭјТчЁЃШ§ЪЧгазжВЛКУгУЃЌ GBKЕФ20902зжжаКмЖрвЛзжЖрТыЁЃФПЧАЭјЩЯЕФГіЭСЮФзжЪ§ОнПтЦеБщДцдкЕФМЏЭтзжЮоЗЈМьЫїЃЌЯдЪО ЁАПЊЬьДАЁБЕШЮЪЬт ЃЌЖМЪЧвђЮЊЮоЗЈНтОіЩЯЪіРЇФбЃЌзіЕНШЋзжЗћДІРэЁЃетИіЮЪЬтЪЧЗёНтОіЃЌЪЧКтСПЪ§ОнПтЪЧЗёОпБИЪ§зжЛЏФкЙІЕФБъзМЁЃ
ЁЁЁЁЮЊгІЖдЩЯЪіФбЬтЃЌЮФзжжааФбаЗЂЭХЖгЭЈЙ§КЃСПЮФЯзгУзжЕФж№вЛећРэЃЌбаЗЂСЫЭъећЕФГіЭСЪЕЮяЮФзжзжЗћМЏБъзМЬхЯЕЃЌБЃжЄСЫЪ§ОнПтЫљгУЫљгазжЗћгыБъзМТыЮЛЕФвЛзжвЛТыОЋШЗЖдгІЃЌБЃжЄСЫЪ§ОнПтИїжжзЪСЯЖМДІгкгааЇЕФЪ§зжЛЏДІРэЕФЗЖЮЇФкЁЃгЩДЫЃЌЁАжаЙњЮФзжжЧФмМьЫїЪ§ОнПтЁБвВОЭГЩЮЊЮЈвЛвЛжжПЩШЋзжЗћЃЈМЏЭтгыМЏФкзжЃЛПЌзжгыдаЮзжЃЛећзжгыЦЋХдЃЉМьЫїЕФГіЭСЮФзжЪ§ОнПтЁЃ
ЁЁЁЁДЫЭтЃЌЪмжЦгкГіЭСЙХЮФзжзЪСЯЪ§зжЛЏИпЖШЕФИДдгадЃЌЦљНёЕФГіЭСЮФзжЭјТчЪ§ОнПтЖдЫљЪеВФСЯЕФМгЙЄГЬЖШВЛИпЃЌМьЫїЙІФмБШНЯЕЅвЛЃЌЛђепЭЈЙ§ЯрЙиГіАцЮяБрКХМьЫїЙХЮФзжЭМЯёВФСЯЃЌЛђепЭЈЙ§ВПЗжЕФМЏФкзжМьЫїЪЭЮФЕФДЧР§ЁЃЯрЖдОжЯоЕФЙІФмНЕЕЭСЫЪ§ОнПтЖдгкбаОПКЭгІгУЕФжЇГжСІЖШЁЃеыЖдетвЛЙВадЮЪЬтЃЌбаОПЭХЖгЖдгІИїИіЪБЖЮжаЙњЮФзжЕФбаОПгыгІгУашвЊЃЌНјааГфЗжЕФЪ§зжЛЏећРэгыЩюЖШМгЙЄЁЃЪЕЯждЪМзЪСЯгыПМЪЭбаОПаХЯЂгыШЋУцЙиСЊЃЌЬиБ№ЪЧзЂжиЙХЮФзжПМЪЭЃЌИњзйЙХЮФзжПМЪЭзюаТНјеЙЃЌВЂвдзжЮЊЖдЯѓЙиСЊПМЪЭаХЯЂЁЃСэЭтЃЌЭъГЩЛђВПЗжЭъГЩГіЭСЮФЯзгяСЯдкгябдЁЂЮФзжгыЮФЛЏЪєадЕШЗНУцЕФЯЕЭГБъзЂЃЌАќРЈЃКзжвхзЂЪЭЁЂгявєБъМЧЁЂвхРрЗжЮіЁЂЦЋХдБъзЂЁЂЙХНёЪЭвхЕШЃЌЪЕЯжЪ§ОнПтФкВПзЪдДШЋУцЪ§зжЯЕСЊЙсЭЈЁЃНјЖјаЮГЩЧАЫљЮДгаЕФЁАПМЪЭЁБЁАЭЈМйЁБЁАЦЋХдЁБЁАзжЬхЗжРрЁБЁАвхРрЗжЮіЁБЕШзЈЬтЪ§ОнПтЯЕСаЃЌДѓДѓЬсЩ§СЫЪ§зжЦНЬЈЕФзЈвЕжЇГХСІЁЃ



